欢迎访问作物学报,今天是
作物学报 ›› 2020, Vol. 46 ›› Issue (10): 1496-1506.doi: 10.3724/SP.J.1006.2020.04028
刘荣1,**( ), 王芳1,**(), 方俐1,**(), 杨涛1, 张红岩1, 黄宇宁1, 王栋1,3, 季一山1, 徐东旭2, 李冠1, 郭瑞军1, 宗绪晓1,*()
), 王芳1,**(), 方俐1,**(), 杨涛1, 张红岩1, 黄宇宁1, 王栋1,3, 季一山1, 徐东旭2, 李冠1, 郭瑞军1, 宗绪晓1,*()
LIU Rong1,**(), WANG Fang1,**(), FANG Li1,**(), YANG Tao1, ZHANG Hong-Yan1, HUANG Yu-Ning1, WANG Dong1,3, JI Yi-Shan1, XU Dong-Xu2, LI Guan1, GUO Rui-Jun1, ZONG Xu-Xiao1,*()
摘要:
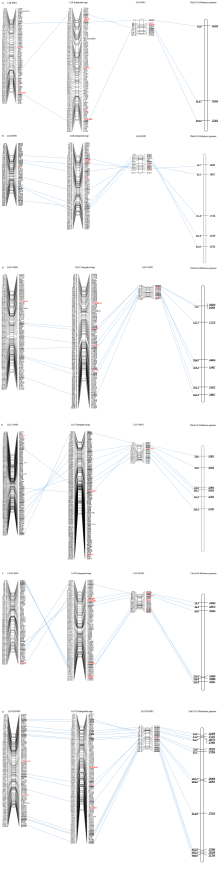
豌豆(Pisum sativum L.)是一种重要的食用豆类作物, 在全世界范围内广泛种植, 既可作为人类食物, 也可作为牲畜饲料。用SSR标记构建的遗传连锁图谱在豌豆和其他作物的标记辅助育种中发挥着重要的作用。尽管对豌豆遗传连锁作图的研究已有悠久历史, 但公众可获得且可转移的SSR标记以及基于遗传独特的中国豌豆种质的高密度遗传连锁图谱仍然有限。为了获得更多可转移的SSR标记和中国豌豆的高密度遗传连锁图谱, 本研究首先从自主开发和文献获取的12,491个全基因组SSR标记中筛选了617个多态性SSR标记, 并用于G0003973×G0005527 F2群体遗传连锁图谱的加密。加密后的图谱全长扩展到5330.6 cM, 包含603个SSR标记, 标记平均间距离8.8 cM, 相比之前的图谱有明显改善。基于上述结果, 我们又筛选了119个具有多态性的SSR标记, 用于构建大样本W6-22600×W6-15174 F2群体的遗传连锁图谱, 新图谱累积长度为1127.1 cM, 包含118个SSR标记, 装配在7条连锁群上。最后, 将来自以上2个遗传图谱的数据进行整合, 得到了一张覆盖范围6592.6 cM的整合图谱, 包含668个SSR标记, 由509个基因组SSR、134个EST-SSR和25个锚定标记组成, 分布在7条连锁群上。这些SSR标记和遗传连锁图谱将为豌豆的遗传研究和标记辅助育种提供有力工具。
| [1] |
Zong X X, Redden R J, Liu Q C, Wang S M, Guan J P, Liu J, Xu Y H, Liu X J, Gu J, Yan L, Ades P, Ford R. Analysis of a diverse global Pisum sp collection and comparison to a Chinese local P. sativum collection with microsatellite markers. Theor Appl Genet, 2009,118:193-204.
doi: 10.1007/s00122-008-0887-z |
| [2] |
Smýkal P, Aubert G, Burstin J, Coyne C J, Ellis N T H, Flavell A J, Ford R, Hýbl M, Macas J, Neumann P, McPhee K E, Redden R J, Rubiales D, Weller J L, Warkentin T D. Pea (Pisum sativum L.) in the genomic era. Agronomy, 2012,2:74-115.
doi: 10.3390/agronomy2020074 |
| [3] |
Tian S J, Kyle W S A, Small D M. Pilot scale isolation of proteins from field peas (Pisum sativum L.) for use as food ingredients. Int J Food Sci Technol, 1999,34:33-39.
doi: 10.1046/j.1365-2621.1999.00236.x |
| [4] |
Santalla M, Amurrio J M, De Ron A M. Food and feed potential breeding value of green, dry and vegetable pea germplasm. Can J Plant Sci, 2001,81:601-610.
doi: 10.4141/P00-114 |
| [5] | FAOSTAT. [2020-03-14]. http://www.fao.org/faostat/en/#data. |
| [6] |
MacWilliam S, Wismer M, Kulshreshtha S. Life cycle and economic assessment of Western Canadian pulse systems: The inclusion of pulses in crop rotations. Agric Syst, 2014,123:43-53.
doi: 10.1016/j.agsy.2013.08.009 |
| [7] | Semagn K, Bjornstad A, Ndjiondjop M N. Principles, requirements and prospects of genetic mapping in plants. Afr J Biotechnol, 2006,5:2569-2587. |
| [8] |
Dirlewanger E, Isaac P G, Ranade S, Belajouza M, Cousin R, de Vienne D. Restriction fragment length polymorphism analysis of loci associated with disease resistance genes and developmental traits in Pisum sativum L. Theor Appl Genet, 1994,88:17-27.
doi: 10.1007/BF00222388 pmid: 24185876 |
| [9] |
Laucou V, Haurogne K, Ellis N, Rameau C. Genetic mapping in pea. 1. RAPD-based genetic linkage map of Pisum sativum. Theor Appl Genet, 1998,97:905-915.
doi: 10.1007/s001220050971 |
| [10] |
Loridon K, McPhee K, Morin J, Dubreuil P, Pilet Nayel M L, Aubert G, Rameau C, Baranger A, Coyne C, Lejeune Henaut I, Burstin J. Microsatellite marker polymorphism and mapping in pea (Pisum sativum L.). Theor Appl Genet, 2005,111:1022-1031.
doi: 10.1007/s00122-005-0014-3 |
| [11] |
DeCaire J, Coyne C J, Brumett S, Shultz J L. Additional pea EST-SSR markers for comparative mapping in pea (Pisum sativum L.). Plant Breed, 2012,131:222-226.
doi: 10.1111/pbr.2011.131.issue-1 |
| [12] |
Mishra R K, Gangadhar B H, Nookaraju A, Kumar S, Park S W. Development of EST-derived SSR markers in pea (Pisum sativum) and their potential utility for genetic mapping and transferability. Plant Breed, 2012,131:118-124.
doi: 10.1111/pbr.2011.131.issue-1 |
| [13] |
Leonforte A, Sudheesh S, Cogan N O I, Salisbury P A, Nicolas M E, Materne M, Forster J W, Kaur S. SNP marker discovery, linkage map construction and identification of QTLs for enhanced salinity tolerance in field pea (Pisum sativum L.). BMC Plant Biol, 2013,13:161.
doi: 10.1186/1471-2229-13-161 pmid: 24134188 |
| [14] |
Sindhu A, Ramsay L, Sanderson L A, Stonehouse R, Li R, Condie J, Shunmugam A S K, Liu Y, Jha A B, Diapari M, Burstin J, Aubert G, Tar’an B, Bett K E, Warkentin T D, Sharpe A G. Gene-based SNP discovery and genetic mapping in pea. Theor Appl Genet, 2014,127:2225-2241.
doi: 10.1007/s00122-014-2375-y |
| [15] |
Sun X L, Yang T, Hao J J, Zhang X Y, Ford R, Jiang J Y, Wang F, Guan J P, Zong X X. SSR genetic linkage map construction of pea (Pisum sativum L.) based on Chinese native varieties. Crop J, 2014,2:170-174.
doi: 10.1016/j.cj.2014.03.004 |
| [16] |
Tayeh N, Aluome C, Falque M, Jacquin F, Klein A, Chauveau A, Berard A, Houtin H, Rond C, Kreplak J, Boucherot K, Martin C, Baranger A, Pilet-Nayel M L, Warkentin T D, Brunel D, Marget P, Le Paslier M C, Aubert G, Burstin J. Development of two major resources for pea genomics: the GenoPea 13.2K SNP Array and a high-density, high-resolution consensus genetic map. Plant J, 2015,84:1257-1273.
doi: 10.1111/tpj.13070 pmid: 26590015 |
| [17] |
Boutet G, Carvalho S A, Falque M, Peterlongo P, Lhuillier E, Bouchez O, Lavaud C, Pilet-Nayel M L, Riviere N, Baranger A. SNP discovery and genetic mapping using genotyping by sequencing of whole genome genomic DNA from a pea RIL population. BMC Genomics, 2016,17:121.
doi: 10.1186/s12864-016-2447-2 pmid: 26892170 |
| [18] |
Ma Y, Coyne C J, Grusak M A, Mazourek M, Cheng P, Main D, McGee R J. Genome-wide SNP identification, linkage map construction and QTL mapping for seed mineral concentrations and contents in pea (Pisum sativum L.). BMC Plant Biol, 2017,17:43.
doi: 10.1186/s12870-016-0956-4 pmid: 28193168 |
| [19] |
Barilli E, Cobos M J, Carrillo E, Kilian A, Carling J, Rubiales D. A high-density integrated DArTseq SNP-based genetic map of Pisum fulvum and identification of QTLs controlling rust resistance. Front Plant Sci, 2018,9:167.
doi: 10.3389/fpls.2018.00167 pmid: 29497430 |
| [20] |
Kreplak J, Madoui M A, Capal P, Novak P, Labadie K, Aubert G, Bayer P E, Gali K K, Syme R A, Main D, Klein A, Berard A, Vrbova I, Fournier C, d’Agata L, Belser C, Berrabah W, Toegelova H, Milec Z, Vrana J, Lee H, Kougbeadjo A, Terezol M, Huneau C, Turo C J, Mohellibi N, Neumann P, Falque M, Gallardo K, McGee R, Tar’an B, Bendahmane A, Aury J M, Batley J, Le Paslier M C, Ellis N, Warkentin T D, Coyne C J, Salse J, Edwards D, Lichtenzveig J, Macas J, Dolezel J, Wincker P, Burstin J. A reference genome for pea provides insight into legume genome evolution. Nat Genet, 2019,51:1411-1422.
doi: 10.1038/s41588-019-0480-1 pmid: 31477930 |
| [21] |
Kalia R K, Rai M K, Kalia S, Singh R, Dhawan A K. Microsatellite markers: an overview of the recent progress in plants. Euphytica, 2011,177:309-334.
doi: 10.1007/s10681-010-0286-9 |
| [22] |
Vieira M L C, Santini L, Diniz A L, Munhoz C D. Microsatellite markers: what they mean and why they are so useful. Genet Mol Biol, 2016,39:312-328.
doi: 10.1590/1678-4685-GMB-2016-0027 pmid: 27561112 |
| [23] |
Ali A, Pan Y B, Wang Q N, Wang J D, Chen J L, Gao S J. Genetic diversity and population structure analysis of Saccharum and Erianthus genera using microsatellite (SSR) markers. Sci Rep, 2019,9:10.
doi: 10.1038/s41598-018-36877-0 pmid: 30626881 |
| [24] |
Hao L, Zhang G S, Lu D Y, Hu J J, Jia H X. Analysis of the genetic diversity and population structure of Salix psammophila based on phenotypic traits and simple sequence repeat markers. PeerJ, 2019,7:e6419.
doi: 10.7717/peerj.6419 pmid: 30805247 |
| [25] |
Choi J K, Sa K J, Park D H, Lim S E, Ryu S H, Park J Y, Park K J, Rhee H I, Lee M, Lee J K. Construction of genetic linkage map and identification of QTLs related to agronomic traits in DH population of maize (Zea mays L.) using SSR markers. Genes Genomics, 2019,41:667-678.
doi: 10.1007/s13258-019-00813-x pmid: 30953340 |
| [26] |
Yang T, Jiang J Y, Zhang H Y, Liu R, Strelkov S, Hwang S F, Chang K F, Yang F, Miao Y M, He Y H, Zong X X. Density enhancement of a faba bean genetic linkage map (Vicia faba) based on simple sequence repeats markers. Plant Breed, 2019,138:207-215.
doi: 10.1111/pbr.2019.138.issue-2 |
| [27] |
Anjani K, Ponukumatla B, Mishra D, Ravulapalli D P. Identification of simple-sequence-repeat markers linked to Fusarium wilt (Fusarium oxysporum f. sp carthami) resistance and marker- assisted selection for wilt resistance in safflower (Carthamus tinctorius L.) interspecific offsprings. Plant Breed, 2018,137:895-902.
doi: 10.1111/pbr.2018.137.issue-6 |
| [28] |
Swathi G, Rani C V D, Md J, Madhav M S, Vanisree S, Anuradha C, Kumar N R, Kumar N A P, Kumari K A, Bhogadhi C, Ramprasad E, Sravanthi P, Raju S K, Bhuvaneswari V, Rajan C P D, Jagadeeswar R. Marker-assisted introgression of the major bacterial blight resistance genes, Xa21 and xa13, and blast resistance gene, Pi54, into the popular rice variety, JGL1798. Mol Breed, 2019,39:12.
doi: 10.1007/s11032-018-0919-6 |
| [29] |
Kumar N, Shikha D, Kumari S, Choudhary B K, Kumar L, Singh I S. SSR-based DNA Fingerprinting and diversity assessment among Indian germplasm of Euryale ferox: an aquatic underutilized and neglected food crop. Appl Biochem Biotechnol, 2018,185:34-41.
doi: 10.1007/s12010-017-2643-9 pmid: 29082475 |
| [30] |
Siew G Y, Ng W L, Tan S W, Alitheen N B, Tan S G, Yeap S K. Genetic variation and DNA fingerprinting of durian types in Malaysia using simple sequence repeat (SSR) markers. PeerJ, 2018,6:e4266.
doi: 10.7717/peerj.4266 pmid: 29511604 |
| [31] |
Tayeh N, Aubert G, Pilet Nayel M L, Lejeune Henaut I, Warkentin T D, Burstin J. Genomic tools in pea breeding programs: Status and perspectives. Front Plant Sci, 2015,6:1037.
doi: 10.3389/fpls.2015.01037 pmid: 26640470 |
| [32] |
Liu R, Fang L, Yang T, Zhang X Y, Hu J G, Zhang H Y, Han W L, Hua Z K, Hao J J, Zong X X. Marker-trait association analysis of frost tolerance of 672 worldwide pea (Pisum sativum L.) collections. Sci Rep, 2017,7:5919.
doi: 10.1038/s41598-017-06222-y pmid: 28724947 |
| [33] |
Wu X B, Li N N, Hao J J, Hu J G, Zhang X Y, Blair M W. Genetic diversity of Chinese and global pea (Pisum sativum L.) collections. Crop Sci, 2017,57:1-11.
doi: 10.2135/cropsci2015.07.0415 |
| [34] |
Milczarski P, Bolibok Brągoszewska H, Myśków B, Stojałowski S, Heller Uszyńska K, Góralska M, Brągoszewski P, Uszyński G, Kilian A, Rakoczy Trojanowska M. A high density consensus map of rye (Secale cereale L.) based on DArT markers. PLoS One, 2011,6:e28495.
doi: 10.1371/journal.pone.0028495 pmid: 22163026 |
| [35] |
Blenda A, Fang D D, Rami J F, Garsmeur O, Luo F, Lacape J M. A high density consensus genetic map of tetraploid cotton that integrates multiple component maps through molecular marker redundancy check. PLoS One, 2012,7:e45739.
doi: 10.1371/journal.pone.0045739 pmid: 23029214 |
| [36] |
Sudheesh S, Lombardi M, Leonforte A, Cogan N O I, Materne M, Forster J W, Kaur S. Consensus genetic map construction for field pea (Pisum sativum L.), trait dissection of biotic and abiotic stress tolerance and development of a diagnostic marker for the er1 powdery mildew resistance gene. Plant Mol Biol Rep, 2015,33:1391-1403.
doi: 10.1007/s11105-014-0837-7 |
| [37] |
Sudheesh S, Rodda M, Kennedy P, Verma P, Leonforte A, Cogan N O I, Materne M, Forster J W, Kaur S. Construction of an integrated linkage map and trait dissection for bacterial blight resistance in field pea (Pisum sativum L.). Mol Breed, 2015,35:185.
doi: 10.1007/s11032-015-0376-4 |
| [38] |
Yang T, Fang L, Zhang X Y, Hu J G, Bao S Y, Hao J J, Li L, He Y H, Jiang J Y, Wang F, Tian S, Zong X X. High-throughput development of SSR markers from pea (Pisum sativum L.) based on next generation sequencing of a purified Chinese commercial variety. PLoS One, 2015,10:e0139775.
doi: 10.1371/journal.pone.0139775 pmid: 26440522 |
| [39] |
Kwon S J, Brown A F, Hu J, McGee R, Watt C, Kisha T, Timmerman-Vaughan G, Grusak M, McPhee K E, Coyne C J. Genetic diversity, population structure and genome-wide marker-trait association analysis emphasizing seed nutrients of the USDA pea (Pisum sativum L.) core collection. Genes Genomics, 2012,34:305-320.
doi: 10.1007/s13258-011-0213-z |
| [40] |
Kaur S J, Pembleton L W, Cogan N O, Savin K W, Leonforte T, Paull J, Materne M, Forster J W. Transcriptome sequencing of field pea and faba bean for discovery and validation of SSR genetic markers. BMC Genomics, 2012,13:104.
doi: 10.1186/1471-2164-13-104 pmid: 22433453 |
| [41] |
Xu S C, Gong Y M, Mao W H, Hu Q Z, Zhang G W, Fu W, Xian Q Q. Development and characterization of 41 novel EST-SSR markers for Pisum sativum (Leguminosae). Am J Bot, 2012,99:E149-E153.
doi: 10.3732/ajb.1100445 |
| [42] | Bordat A, Savois V, Nicolas M, Salse J, Chauveau A, Bourgeois M, Potier J, Houtin H, Rond C, Murat F, Marget P, Aubert G, Burstin J. Translational genomics in legumes allowed placing in silico 5460 unigenes on the pea functional map and identified candidate genes in Pisum sativum L. G3: Genes Genom Genet 2011,1:93-103. |
| [43] | 顾竟, 李玲, 宗绪晓, 王海飞, 关建平, 杨涛. 豌豆种质表型性状SSR标记关联分析. 植物遗传资源学报, 2011,12:833-839. |
| Gu J, Li L, Zong X X, Wang H F, Guan J P, Yang T. Association analysis between morphological traits of pea and its polymorphic SSR markers. J Plant Genet Resour, 2011,12:833-839 (in Chinese with English abstract). | |
| [44] |
Burstin J, Deniot G, Potier J, Weinachter C, Aubert G, Barranger A. Microsatellite polymorphism in Pisum sativum. Plant Breed, 2001,120:311.
doi: 10.1046/j.1439-0523.2001.00608.x |
| [45] |
Dellaporta S L, Wood J, Hicks J B. A plant DNA minipreparation: version II. Plant Mol Biol Rep, 1983,1:19-21.
doi: 10.1007/BF02712670 |
| [46] |
Meng L, Li H H, Zhang L Y, Wang J K. QTL IciMapping: integrated software for genetic linkage map construction and quantitative trait locus mapping in biparental populations. Crop J, 2015,3:269-283.
doi: 10.1016/j.cj.2015.01.001 |
| [47] |
Voorrips R E. MapChart: software for the graphical presentation of linkage maps and QTLs. J Hered, 2002,93:77-78.
doi: 10.1093/jhered/93.1.77 pmid: 12011185 |
| [48] |
Parida S K, Kalia S K, Kaul S, Dalal V, Hemaprabha G, Selvi A, Pandit A, Singh A, Gaikwad K, Sharma T R, Srivastava P S, Singh N K, Mohapatra T. Informative genomic microsatellite markers for efficient genotyping applications in sugarcane. Theor Appl Genet, 2009,118:327-338.
doi: 10.1007/s00122-008-0902-4 |
| [49] | Kamaluddin , Khan M A, Kiran U, Ali A, Abdin M Z, Zargar M Y, Ahmad S, Sofi P A, Gulzar S. Molecular markers and marker-assisted selection in crop plants. In: Abdin M Z, Kiran U, Kamaluddin, Ali A, eds. Plant Biotechnology: Principles and Applications. Singapore: Springer Singapore, 2017. pp 295-328. |
| [50] |
Nadeem M A, Nawaz M A, Shahid M Q, Doğan Y, Comertpay G, Yıldız M, Hatipoğlu R, Ahmad F, Alsaleh A, Labhane N, Özkan H, Chung G, Baloch F S. DNA molecular markers in plant breeding: current status and recent advancements in genomic selection and genome editing. Biotechnol Biotechnol Equip, 2018,32:261-285.
doi: 10.1080/13102818.2017.1400401 |
| [51] |
Varshney R K, Graner A, Sorrells M E. Genic microsatellite markers in plants: features and applications. Trends Biotechnol, 2005,23:48-55.
doi: 10.1016/j.tibtech.2004.11.005 pmid: 15629858 |
| [52] |
Smýkal P, Hybl M, Corander J, Jarkovsky J, Flavell A J, Griga M. Genetic diversity and population structure of pea (Pisum sativum L.) varieties derived from combined retrotransposon, microsatellite and morphological marker analysis. Theor Appl Genet, 2008,117:413-424.
doi: 10.1007/s00122-008-0785-4 |
| [53] |
宗绪晓, 关建平, 王述民, 刘庆昌. 中国豌豆地方品种SSR标记遗传多样性分析. 作物学报, 2008,34:1330-1338.
doi: 10.3724/SP.J.1006.2008.01330 |
| Zong X X, Guan J P, Wang S M, Liu Q C. Genetic diversity among Chinese pea (Pisum sativum L.) landraces revealed by SSR markers. Acta Agron Sin, 2008,34:1330-1338 (in Chinese with English abstract). | |
| [54] |
Zong X X, Ford R, Redden R R, Guan J P, Wang S M. Identification and analysis of genetic diversity structure within Pisum genus based on microsatellite markers. Agric Sci China, 2009,8:257-267.
doi: 10.1016/S1671-2927(08)60208-4 |
| [55] |
宗绪晓, 关建平, 王述民, 刘庆昌, Redden R R, Ford R. 国外栽培豌豆遗传多样性分析及核心种质构建. 作物学报, 2008,34:1518-1528.
doi: 10.3724/SP.J.1006.2008.01518 |
| Zong X X, Guan J P, Wang S M, Liu Q C, Redden R R, Ford R. Genetic diversity and core collection of alien Pisum sativum L. germplasm. Acta Agron Sin, 2008,34:1518-1528 (in Chinese with English abstract). | |
| [56] | Prakash N, Kumar R, Choudhary V K, Singh C M. Molecular assessment of genetic divergence in pea genotypes using microsatellite markers. Legume Res, 2016,39:183-188. |
| [57] |
Duarte J, Riviere N, Baranger A, Aubert G, Burstin J, Cornet L, Lavaud C, Lejeune Henaut I, Martinant J P, Pichon J P, Pilet Nayel M L, Boutet G. Transcriptome sequencing for high throughput SNP development and genetic mapping in pea. BMC Genom, 2014,15:126.
doi: 10.1186/1471-2164-15-126 |
| [58] |
Guindon M F, Martin E, Cravero V, Gali K K, Warkentin T D, Cointry E. Linkage map development by GBS, SSR, and SRAP techniques and yield-related QTLs in pea. Mol Breed, 2019,39:54.
doi: 10.1007/s11032-019-0949-8 |
| [59] |
Aubert G, Morin J, Jacquin F, Loridon K, Quillet M C, Petit A, Rameau C, Lejeune Henaut I, Huguet T, Burstin J. Functional mapping in pea, as an aid to the candidate gene selection and for investigating synteny with the model legume Medicago truncatula. Theor Appl Genet, 2006,112:1024-1041.
doi: 10.1007/s00122-005-0205-y |
| [60] |
Duarte J, Riviere N, Baranger A, Aubert G, Burstin J, Cornet L, Lavaud C, Lejeune Henaut I, Martinant J P, Pichon J P, Pilet Nayel M L, Boutet G. Transcriptome sequencing for high throughput SNP development and genetic mapping in pea. BMC Genom, 2014,15:126.
doi: 10.1186/1471-2164-15-126 |
| [61] |
Sindhu A, Ramsay L, Sanderson L A, Stonehouse R, Li R, Condie J, Shunmugam A S K, Liu Y, Jha A B, Diapari M, Burstin J, Aubert G, Tar’an B, Bett K E, Warkentin T D, Sharpe A G. Gene-based SNP discovery and genetic mapping in pea. Theor Appl Genet, 2014,127:2225-2241.
doi: 10.1007/s00122-014-2375-y |
| [62] |
Sybenga J. Recombination and chiasmata: few but intriguing discrepancies. Genome, 1996,39:473-484.
doi: 10.1139/g96-061 pmid: 18469909 |
| [63] |
Knox M R, Ellis T H N. Excess heterozygosity contributes to genetic map expansion in pea recombinant inbred populations. Genetics, 2002,162:861-873.
pmid: 12399396 |
| [64] | Truong S K, McCormick R F, Morishige D T, Mullet J E. Resolution of genetic map expansion caused by excess heterozygosity in plant recombinant inbred populations. G3: Genes Genom Genet, 2014,4:1963-1969. |
| [65] |
Ellis T H, Turner L, Hellens R P, Lee D, Harker C L, Enard C, Domoney C, Davies D R. Linkage maps in pea. Genetics, 1992,130:649-663.
pmid: 1551583 |
| [1] | 胡文静, 李东升, 裔新, 张春梅, 张勇. 小麦穗部性状和株高的QTL定位及育种标记开发和验证[J]. 作物学报, 2022, 48(6): 1346-1356. |
| [2] | 陈小红, 林元香, 王倩, 丁敏, 王海岗, 陈凌, 高志军, 王瑞云, 乔治军. 基于高基元SSR构建黍稷种质资源的分子身份证[J]. 作物学报, 2022, 48(4): 908-919. |
| [3] | 张霞, 于卓, 金兴红, 于肖夏, 李景伟, 李佳奇. 马铃薯SSR引物的开发、特征分析及在彩色马铃薯材料中的扩增研究[J]. 作物学报, 2022, 48(4): 920-929. |
| [4] | 王琰琰, 王俊, 刘国祥, 钟秋, 张华述, 骆铮珍, 陈志华, 戴培刚, 佟英, 李媛, 蒋勋, 张兴伟, 杨爱国. 基于SSR标记的雪茄烟种质资源指纹图谱库的构建及遗传多样性分析[J]. 作物学报, 2021, 47(7): 1259-1274. |
| [5] | 周新桐, 郭青青, 陈雪, 李加纳, 王瑞. GBS高密度遗传连锁图谱定位甘蓝型油菜粉色花性状[J]. 作物学报, 2021, 47(4): 587-598. |
| [6] | 韩贝, 王旭文, 李保奇, 余渝, 田琴, 杨细燕. 陆地棉种质资源抗旱性状的关联分析[J]. 作物学报, 2021, 47(3): 438-450. |
| [7] | 刘少荣, 杨扬, 田红丽, 易红梅, 王璐, 康定明, 范亚明, 任洁, 江彬, 葛建镕, 成广雷, 王凤格. 基于农艺及品质性状与SSR标记的青贮玉米品种遗传多样性分析[J]. 作物学报, 2021, 47(12): 2362-2370. |
| [8] | 郭艳春, 张力岚, 陈思远, 祁建民, 方平平, 陶爱芬, 张列梅, 张立武. 黄麻应用核心种质的DNA分子身份证构建[J]. 作物学报, 2021, 47(1): 80-93. |
| [9] | 王恒波,祁舒婷,陈姝琦,郭晋隆,阙友雄. 甘蔗栽培种单倍体基因组SSR位点的发掘与应用[J]. 作物学报, 2020, 46(4): 631-642. |
| [10] | 张红岩,杨涛,刘荣,晋芳,张力科,于海天,胡锦国,杨峰,王栋,何玉华,宗绪晓. 利用EST-SSR标记评价羽扇豆属(Lupinus L.)遗传多样性[J]. 作物学报, 2020, 46(3): 330-340. |
| [11] | 张力岚, 张列梅, 牛焕颖, 徐益, 李玉, 祁建民, 陶爱芬, 方平平, 张立武. 黄麻SSR标记与纤维产量性状的相关性[J]. 作物学报, 2020, 46(12): 1905-1913. |
| [12] | 胡文静,张勇,陆成彬,王凤菊,刘金栋,蒋正宁,王金平,朱展望,徐小婷,郝元峰,何中虎,高德荣. 小麦品种扬麦16赤霉病抗扩展QTL定位及分析[J]. 作物学报, 2020, 46(02): 157-165. |
| [13] | 叶卫军,陈圣男,杨勇,张丽亚,田东丰,张磊,周斌. 绿豆SSR标记的开发及遗传多样性分析[J]. 作物学报, 2019, 45(8): 1176-1188. |
| [14] | 崔翠,程闯,赵愉风,郜欢欢,王瑞莉,王刘艳,周清元. 52份豌豆种质萌发期耐铝毒性的综合评价与筛选[J]. 作物学报, 2019, 45(5): 798-805. |
| [15] | 童治军,张谊寒,陈学军,曾建敏,方敦煌,肖炳光. 雪茄烟品种Beinhart1000-1赤星病抗性基因的QTL定位[J]. 作物学报, 2019, 45(3): 477-482. |
|
||