


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
贵州作物种质资源调查数据可视化研究
[陈丽娜1, 2  , 司海平
, 司海平3 , 方沩2 , 陈彦清2 , 曹永生2, * ]
, 司海平]
|
|


第一作者联系方式: E-mail:chenlina@cgris.org
“贵州农业生物资源调查”项目产生了大量数据资料, 采用有效的方法分析这些资料有利于全面了解当地生物资源的利用和保护情况, 可为决策部门制定资源保护策略和进一步科学研究提供依据。分析了不同的可视化方法, 针对以往调查数据研究结果呈现不直观等特点, 本文采用Microsoft Excel、GIS和R多种手段对调查数据进行可视化研究, 并分析了可视化的结果。试验结果表明, 电子表格可做简单的统计分析; 空间数据可视化方法可用于数据校验、显示种质资源富集程度; 统计分析可视化方法整合了不同类型的数据, 可用于挖掘出隐藏在数据中的信息。多种数据可视化手段可使数据及分析结果以更直观的形式呈现, 有助于全面了解生物资源, 促进资源充分利用。分析了作物种质资源调查过程中存在的问题, 对进一步规范种质调查数据提出了建议。
The large amounts of data derived from the project of “Agro-biological Resources Investigation in Guizhou Province” require analyzing in effective methods and providing comprehensive information on conservation and utilization of biological resources in this province to support local policy makers. Visualized and intuitive demonstration of data analysis is a well-liked but ignored in previous systems regarding resource investigation and data excavation. In this study, we compared several visualization methods, including Microsoft Excel, GIS, and R software, and proposed an effective strategy. We found that the spreadsheet was suitable for simple data analysis, spatial data visualization method was suitable for validating data and showing richness of resources, and statistical analysis visualization method had the advantage of mining hiding information because it could integrate different types of data. Using several visualization methods can make the intuitive results of data analysis, from which we are able to better understand germplasm resources and promote utilization efficiency of germplasm resources. This article also discussed the existing problems and data-standardizing proposals in the investigation of crop germplasm resources.
农作物种质资源是一个国家重要的战略资源, 是作物遗传改良和相关基础研究的物质基础[1], 农作物种质资源的拥有和开发利用程度已成为衡量一个国家综合国力和可持续发展能力的重要指标之一。由中国农业科学院牵头的国家科技基础性工作专项“ 贵州农业生物资源调查” 项目(编号为2012FY110200)于2012年启动, 3年来, 先后共普查了贵州省42个县(市), 4次系统性调查了其中的21个县(市), 主要调查了粮食作物、蔬菜、果树及药用植物等作物种质资源, 获得了大量种质资源及原始数据资料。这些宝贵的数据资料是关于生物资源的基础数据, 可以帮助了解贵州省作物种质资源的分布及变化情况, 为深入研究与资源保护提供支撑。由于种质资源收集费时费力, 通常是分多个小组多时段进行的, 尽管有“ 农作物种质资源收集技术规程” 作指导, 并通过“ 调查数据录入系统” 录入数据, 但由于收集者技术水平等各方面因素的影响, 收集到的数据必须通过分类、整理、校对、整合及分析, 才能更大效能地发挥作用。在数据量日益增长的背景下, 通过数据分析可以发现隐藏在海量数据中的信息, 而信息以可视化的形式呈现显得尤为重要。
可视化技术给数据分析提供了新手段, 可以使数据及分析结果以更直观的形式呈现, 越来越广泛地被用在各种数据分析领域。可视化最初主要应用在科学计算领域, 称为科学计算可视化, 它是指利用计算机图形学和图像处理等技术, 将数据转换成图形或图像, 在屏幕上显示并进行交互处理的理论、方法和技术[2]。后来逐渐发展成为包括数据可视化和信息可视化等一系列分支学科[3], 已经成为研究数据表示、数据处理和决策分析的综合技术。科学计算可视化侧重于处理科学计算或工程测量获得的数据, 处理该类数据的主要方法大致可分为基于矢量场的图标法、流线法和纹理法等[4, 5, 6], 基于标量场的颜色法、等值线(面)法、体绘制法等[7, 8]。随着可视化应用领域的扩展, 可视化越来越多地应用于处理抽象的非数值数据, 旨在借助于图形化手段, 研究大规模非数值信息资源的视觉呈现, 清晰有效地传达与沟通信息, 帮助人们理解和分析数据。常用的处理抽象数据的可视化方法主要包括几何可视化方法[9, 10, 11, 12]、图标可视化方法[13, 14]、层次可视化方法[15, 16]、基于GIS的可视化方法[17, 18]、多视图的可视化方法[19]等。可视化方法众多, 难以选择, 往往根据不同领域、不同目的而采用合适的方法。在数据可视化方面, 更侧重于使用软件工具来分析数据, 表达结果。目前, 对农作物种质资源调查数据的分析, 有直接的统计分析处理[20, 21], 但很少有文献介绍具体的工具或方法, 结果呈现也并不直观。有基于GIS对农作物种质资源数据的空间分析[22, 23, 24], 这些研究的重点集中在种质资源的地理分布方面, 并没有深入研究数据之间的关系; 还有对种质资源数据的关联挖掘分析[25, 26], 但这些研究只针对种质资源某一方面, 没有着眼于种质资源数据整体。当前, 对数据分析尤其是大数据分析的标准流程为数据收集、数据集成、数据分析及数据可视化。用可视化的图形图像方式展示数据分析的结果, 已经成为必然的趋势。因此, 根据作物种质资源调查数据的特点, 利用Excel进行基本的可视化分析, 利用GIS进行生态分布研究, 利用R进行较复杂的统计分析, 多种可视化手段为作物种质资源调查数据分析服务。期望调查数据能以更直观、更详尽的形式呈现给使用者, 并对作物种质资源调查数据规范化提出了建议。
以“ 贵州农业生物资源调查” 相关资料为基础, 数据包括GPS信息、采集小组信息、调查表信息、访谈信息、样本图片信息及与民族有关的信息等, 通过汇总、整合、预处理(校正、补充完善信息项不全的数据), 规范了4600余份调查资源的相关资料信息。研究中用到的贵州省生态地理资料包括贵州省地图资料(来源于国家基础地理信息中心), 贵州省温度、气候及降雨等资料(来源于DIVA-GIS网站), 贵州省2010年人口普查资料及《贵州统计年鉴2013》中与人口和民族有关的数据资料。
本文采用多种可视化手段研究作物种质资源调查数据。试验所用工具包括Microsoft Excel、DIVA-GIS和R, 不同工具适用于不同的需求。
Microsoft Excel主要擅长数据的计算, 其简单易行的图表功能给非专业人员快速分析数据的能力, 长期以来一直在数据可视化领域占有重要地位。尽管作为一款可视化入门级的工具, 但Excel也可以可视化比较复杂的数据, 比如单元格的热点图和散点图。尤其是2013年微软发布了3D可视化插件GeoFlow, 用户在Microsoft Excel 2013版本上安装插件后, 可以将数据与电子地图交互, 画出热力图和气泡图等复杂图形。但该软件在绘制复杂图形时比较麻烦, 且其颜色、线条和风格难以自由设置, 绘制的图形不够精美。
空间数据可视化需要用到GIS工具。GIS软件很多, 如ArcGIS、MapGIS、SuperMap等, 这些软件功能强大, 但是也存在系统庞大或付费等问题。而农作物种质资源调查数据的空间可视化分析, 主要是想得到有关作物的生态地理分布信息。由国际马铃薯中心开发的一款小型软件DIVA-GIS, 完全免费, 且可以方便地在网站上获取世界陆地上任意地点的气候信息, 其下载地址为http://www.diva-gis. org/, 它在空间数据分析方面具有独特优势[27], 利用它可以简单快捷地实现生物地图的绘制, 但不适用作复杂数据分析。
统计分析可视化可利用R软件实现。R作为一个统计分析、绘图的语言和操作环境, 因其跨平台、开源和免费等特点, 越来越受到用户青睐[28]。尤其是R有数以千计的安装包, 使用这些软件包可以胜任任何复杂的数据分析, 且其可视化能力非常强, 可以做出各种炫目的图表, 绘制精美的图形。因其是命令行操作, 入门门槛比较高, 需要具有编程能力, 但一旦掌握之后, 数据处理将非常方便。将统计分析与可视化结合具有广阔的应用前景。
假定想要了解贵州农业生物资源调查数据中不同地方各类作物种质资源的收集情况, 根据2012年5月至2014年10月进行的4次系统调查, 调查地点涵盖贵州省东、西、南、北、中各个不同地理位置, 涉及21个县。首先对调查数据按作物分类, 再使用Excel排序、筛选等, 通过计算得出每个县各类资源的具体数目, 最后使用图表功能将结果展示出来, 如图1所示。
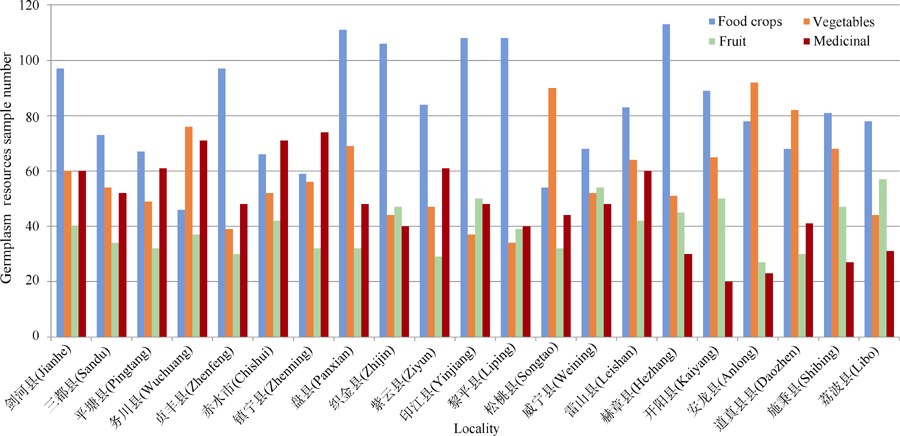 | 图1 贵州调查数据各县(市)不同种类种质资源收集情况Fig. 1 Chart of germplasm resources investigation sample in different counties of Guizhou |
该调查资源包括粮食作物、蔬菜、果树和药用植物四大类。从图1可见, 21个县调查收集得到的资源中, 粮食作物种类都相对较多, 说明粮食作物在贵州仍然是主导, 其多样性在一定程度上得以保存。务川、安龙、松桃和道真各县收集的蔬菜资源数目超过了粮食作物数目; 织金、印江、威宁和荔波各县的果树资源较为丰富, 种类仅次于粮食作物; 务川、赤水和镇宁各县的药用植物资源最为丰富, 收集资源数超过了粮食作物数。使用Excel作基本分析, 简单易操作, 可以横向对比, 能直观地表达出每个地方各类资源的不同, 是快速分析数据的理想工具。但如果数据的分类太多, 图片会显得杂乱, 不利于数据分析。而且, 如果想再进一步分析形成这些不同的原因, 比如当地的民族、经济、地理特性等对作物多样性的影响, Excel就很难再发挥作用, 必须寻求其他方法来解决。
农作物种质资源调查数据带有经纬度坐标信息, 可使用空间数据可视化方法分析。使用DIVA-GIS工具校验数据, 除显示种质资源富集程度, 还可显示资源所在地的海拔、平均温度和年降雨量等信息。
2.2.1 利用DIVA-GIS校验数据和显示资源分布
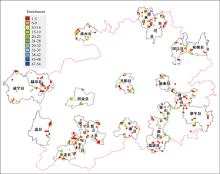
将贵州地图和带有空间坐标信息的贵州生物资源调查数据导入DIVA-GIS软件, 可得调查种质资源分布情况, 如图2所示。
 | 图2 贵州调查资源地理分布Fig. 2 Geographic distribution of resources investigated in Guizhou |
图2显示了贵州调查中全部21个县的种质资源分布情况, 每个点代表一个资源采集点, 一个坐标点有可能收集多份资源。分别使用“ ○” 、“ □” 、“ Δ ” 和“ +” 符号代表第1、第2、第3和第4次调查的坐标点, 第1次调查地点主要在贵州东南部; 第2次调查地点主要在贵州南部和贵州北部; 第3次和第4次则兼顾了贵州的各个方位, 说明资源收集工作分步骤有计划地进行, 兼顾贵州省的各个位置。另外, 在汇集数据时发现, GPS数据在录入时经常会出错, 比如漏掉小数点或小数点位置不对等, 导致某个地方的采集坐标点出现在另外一个地方, 使用DIVA- GIS软件可以非常方便地校验明显不合理的数据。在DIVA-GIS地理分布图中, 将光标定位在待校验点, 即弹出信息框显示该调查坐标点的信息, 包括资源名称、地点、采集人及经纬度信息等。从图2可以看到, 镇远县境内出现了一个单独的坐标点, 但4次系统调查均没有对该县做大规模调查, 因此需要校验。查询提交的原始数据, 发现该资源确实是镇远县资源, 是采集于镇远县农业局经作站的蔬菜资源, 有关该资源的详细信息会在提示框中显示。由此可见, 使用GIS工具有利于全面了解资源的分布情况, 也有利于收集资源的准确和进一步规范化。
2.2.2 利用DIVA-GIS进行统计计算 使用DIVA-GIS软件还可以进行简单的统计计算。在DIVA-GIS中导入贵州调查数据和地图, 并进行统计计算, 可得到图3所示的贵州调查资源富集情况。
 | 图3 贵州调查资源的地理富集Fig. 3 Geographic enrichment diagram of resources investigated in Guizhou |
图3中每个采集点资源的丰富程度用不同颜色的方块表示, 代表了该点收集的资源数量, 也可以认为该点资源的丰富程度。从红、黄到蓝依次表明该点资源的数量在增加, 也即资源越来越丰富。但通过分析发现, 在资源采集过程中, 各个小组对于坐标定位方法不统一, 有些小组严格以每家每户为坐标, 而有些调查小组则以自然村为单位作为坐标, 导致并不能准确地反映该坐标点资源的丰富程度。因此, 在地理坐标定位规整统一的情况下, 资源的富集统计分析才真实可靠。
2.2.3 利用DIVA-GIS显示地理数据 DIVA-GIS网站上有世界各地近几十年的地理、气候数据, 可以使用该软件方便地显示出贵州省任意地点的海拔、平均气温和年降雨量等气候信息。图4是贵州省的海拔、平均气温和平均降雨量图。
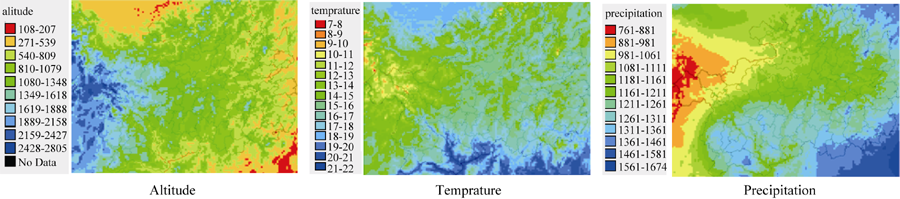 | 图4 贵州海拔、平均气温和年降雨量图Fig. 4 Maps of altitude, average temperature, and annual precipitation in Guizhou |
海拔、平均气温和年降雨量的配色均是由红绿蓝依次增加。由图4可以看到, 贵州海拔西高东低, 威宁县和赫章县的大部分地区海拔在1600 m以上, 而东部的黎平县和松桃县的海拔则大部分在800 m以下; 贵州大部分的平均气温在11~18℃之间; 贵州西部大部分地区平均降雨量小于1000 mm, 东南部大部分地区平均降雨量超过1300 mm。特定的地理和气候条件对作物的分布有一定影响, 比如位于黔西北的威宁彝族回族苗族自治县, 低纬度、高海拔(平均海拔2300 m左右, 海拔最高点为2879.6 m, 最低点1234 m), 平均气温在10~12℃之间, 年平均日照时数为1812 h, 降雨量较少, 特殊的地理位置和气候形成了当地特有资源, 如金铁锁(也叫撑药, 编号为201352534)。利用气候数据可以分析资源的生态地理分布原因, 但一个地区的作物种质资源分布受多个因素的影响, 除了海拔、经纬度等空间信息外, 还有民族习俗、人口等各种因素, 应综合分析。
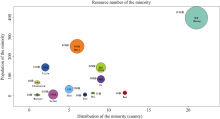
贵州是多民族省份, 全省共有49个民族, 少数民族数量仅次于云南, 居全国第二, 少数民族风俗习惯对种质资源多样性的影响是最重要的因素之一。据贵州省2010年第6次人口普查数据, 全省常住人口中, 汉族有2219.8485万人, 占63.89%, 各少数民族有1254.7983万人, 占36.11%, 汉族仍占贵州省人口的大多数。但采集的资源中, 汉族提供的种质资源只占全部资源的16%, 而其他各少数民族则提供了贵州省种质资源的84%。使用R软件, 综合贵州调查数据、民族数据和人口数据等, 分析少数民族人数和分布对资源收集数量的影响。为了处理方便, 对各少数民族分布进行数字化处理, 使用R软件绘制各民族资源收集情况气泡图(使用R软件graphics包中的symbols函数), 得到的各少数民族资源收集情况如图5所示。
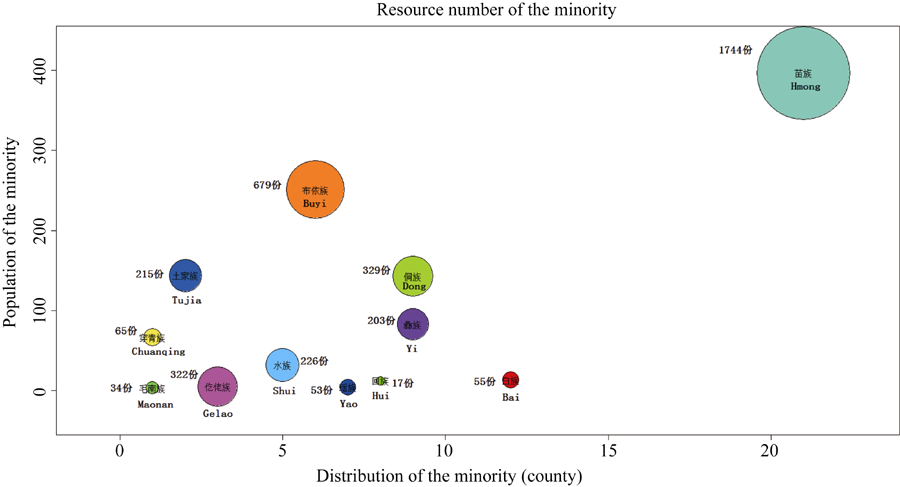 | 图5 贵州省各少数民族资源收集情况Fig. 5 Bubble chart of resources collection number of some minorities in Guizhou |
各少数民族中, 苗族收集的资源数目最多, 有1744份, 占全部资源的36%。这是因为苗族人数最多, 有397万人, 分布也最广, 遍布调查涉及的21个县; 其次是布依族, 收集的资源数为679份, 占全部资源的14%, 布依族有251万人, 分布也较广; 分布比较集中的仡佬族、水族和土家族, 人数虽少, 但较好地保留了本民族特色(图5)。
自20世纪70年代末第2次全国性资源征集至今, 已过去30多年了, 资源收集流程及标准制定等方面已经比较规范[29], 但在数据分析过程中发现, 具体每个资源收集者在遵守标准方面, 仍不十分严格, 有些数据项缺失, 对可视化工作带来了一些难题, 无法作定量分析。因此, 为便于调查数据的可视化分析, 针对资源调查存在的问题进行分析, 并提出以下建议: (1)资源的大类划分仍不是很清楚, 有交叉。在贵州收集的种质资源中, 有些收集者将资源分为“ 粮食作物” 、“ 蔬菜” 、“ 果树” 和“ 药用植物” 四大类; 而有些收集者则又加上“ 蔬菜及一年生经济作物” 、“ 果树及多年生经济作物” ; 还有再细分为“ 多年生经济作物” 、“ 粮油” 、“ 蔬菜及多年生经济作物” 和“ 食用菌” 等种类, 导致资源的分类混乱。而且一些油料作物, 包括“ 花生” 、“ 向日葵” 、“ 芝麻” 和“ 油菜” 的归类也比较乱, 有些将其归于“ 蔬菜及一年生经济作物” , 而有些则归于“ 粮食作物” , 无法比较精准地统计出各类资源的数目。虽然每种归类方法都有自己的合理性, 但还是建议对资源的大类划分尽量统一, 便于对调查资源的准确归类。(2)资源的特性“ 特异” 、“ 特有” 、“ 特优” 、“ 特用” 和“ 一般” 的划分依据不很明确。很多分类间也都有交叉, 同时既是“ 特优” 和“ 特用” , 还有很多资源的这组特性是“ 不明确” 和空白。建议用更详细的指标来划分资源的类型, 以便快速区分出优质资源, 优先针对性地进一步鉴定分析。(3)资源表型信息不完全。大多资源的表型信息都比较笼统, 有些资源, 比如采集号为2012521100的“ 长辣椒” , 特性只是“ 品质优” , 还有很多资源的表型信息根本就没有。建议资源采集时尽量比较多地描述表型信息, 分不同指标更详细的描述, 这样可为数据可视化提供便利, 有利于对资源进行挖掘分析。(4)资源采集过程中坐标的定位不统一。有些小组严格以每家每户为坐标, 而有些调查小组则以自然村为单位作为坐标。因我国村级行政单位都不大, 居住也相对比较集中, 建议以村小组为统一的坐标定位点, 以防止标准的不统一导致使用GIS工具分析时产生误差。(5)大量调查数据没有被充分利用。贵州调查数据资料, 共有超过100GB的数据, 其中大部分是图片、录音等, 文字资料只占不到10%, 大量的图片等资料没有被很好利用。建议采集时图片大小统一、命名统一, 以数据库的方式统一管理, 提高资料的利用效率, 避免浪费辛苦采集得到的数据资料。
本研究综合使用多种可视化手段分析贵州种质资源调查数据, 电子表格适用快速对数据作简单统计分析; 空间数据可视化方法适合生物资源地理分布的研究, 可进行数据校验、显示种质资源富集程度; 统计分析方法可挖掘出隐藏在数据中的信息, 但R软件高级应用需要有编程技能。可视化手段能使调查数据以更直观的形式展示, 有利于全面了解贵州生物资源的利用和保护情况, 为进一步的科学研究提供依据。种质资源工作包括资源的收集、保存、鉴定评价和创新利用, 其最终目的是创新利用。目前鉴定评价数据不完整, 大量的基因数据没有整合, 未来希望对鉴定评价数据进行可视化研究, 进一步整合种质资源基因数据, 并结合生物信息学的知识进行可视化分析。
致谢: 本项目主要数据来源于国家农作物种质资源平台信息中心和国家科技基础性工作专项(2012FY110200), 特此感谢。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|