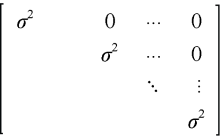运用广义线性混合模型分析随机区组重复测量的试验资料
张久权, 闫慧峰, 褚继登, 李彩斌
作物学报
2021, 47 ( 2):
294-304.
DOI: 10.3724/SP.J.1006.2021.04085
重复测量试验对同一受试对象进行多次测量, 各时间点数据间存在自相关性, 进行方差分析和均值比较时需要进行特殊处理。虽然此方法在农业等研究领域运用十分广泛, 但目前有效地相关统计方法鲜见。为了建立操作简单、实用性强、结果可靠的统计分析方法, 本研究采用SAS的广义线性混合模型(Generalized Linear Mixed Models, GLIMMIX), 以随机区组重复测量试验资料为例, 说明了协方差结构筛选、方差分析和均值比较的具体方法。结果表明, 用传统的裂区设计、多变量统计等方法会造成资料信息浪费, 统计功效降低, 缺区无法处理等问题, 甚至会导致错误的结论。GLIMMIX能很好地处理自相关问题, 功能强大, 结果可靠, 使用简单, 允许缺区, 是进行重复测量试验资料方差分析和均值比较的理想方法。目前在国内将其运用到农学类试验数据的统计分析的相关报道鲜见, 该文在本领域具有很强的实用性和创新性。
准则
Criteria | 方差分量
VC | 复合对称
CS | 不规则
UN | 空间幂相关
SP | 一阶自回归AR(1) | 循环相关
TOEP | 一阶前依赖ANTE(1) | | -2logL | 790.7 | 790.7 | 638.5 | 790.4 | 790.4 | 677.0 | 790.7 | | AIC | 792.7 | 794.7 | 694.5 | 794.4 | 794.4 | 703.0 | 792.7 | | AICC | 792.7 | 794.8 | 711.3 | 794.5 | 794.5 | 706.3 | 792.7 | | BIC | 794.0 | 797.2 | 730.8 | 797.0 | 792.6 | 691.3 | 794.0 | | CAIC | 795.0 | 799.2 | 758.8 | 799.0 | 794.6 | 704.3 | 795.0 | | HQIC | 793.0 | 795.4 | 705.3 | 795.2 | 790.8 | 679.5 | 793.0 |
View table in article
表3
不同协方差结构模型拟合性(土柱试验)
正文中引用本图/表的段落
程序说明: 输入代码时注意分号为英文字符。数据存放在E:\数据\N.xls sheet1里, 格式见表1。程序(1)读取Excel文件的数据。程序(2)~(8)内容基本相同, 仅在“type =”后的协方差结构选项不同。对某些协方差结构, 包括一阶自回归[autoregressive(1), AR(1)]、循环相关(toeplitz, TOEP)、一阶前依赖[antedependence, ANTE(1)]等协方差结构, 需要考虑对象间误差, 因此需要增加random block core(Rain N)语句[15]。程序(2)~(8)调用GLIMMIX过程, 分别采用方差分量结构(variance components, VC)、复合对称结构(compound symmetry, CS)、不规则结构(unstructured, UN)、空间幂相关结构[space power, SP(POW)]、一阶自回归[AR(1)]、循环相关结构(TOEP)、一阶前依赖结构[ANTE(1)]模型进行方差分析。Class语句列出所有的分类变量。Model语句根据上文(1)式编写, Model语句后仅需要列出固定效应[4], 注意此与mixed的不同。Rain|N|times表示3个因素的主效应、2级和3级交互作用效应的线性组合。采用KR法对标准误和自由度进行修正[16]。random_residual_语句相当于mixed模型中的repeated语句[5]。选项type指定协方差结构类型。选项sub指定数据集中的受试对象(subject), 本例中为土柱(core), 即小区, 若为单因素试验, 直接指定对象名称; 若为多因素试验, 则在对象名称后加因素名称, 并加“()”。ods output语句输出模型拟合信息fitstatistics。程序(9)建立宏rename, 对数据集中已有变量名value更名, 否则原有数据列value的数据会被覆盖[17]。程序(10)对不同协方差结构拟合参数进行合并, 以便程序(11)输出拟合结果, 为挑选最佳协方差结构提供依据。
根据统计学理论, 选用协方差结构模型时, 可参考赤池信息准则(akaike information criterion, AIC)、为小样本修正的赤池信息准则(akaike information corrected criterion, AICC)、修正的赤池信息准则(corrected akaike information criterion, CAIC)、贝叶斯信息准则(bayesian information criterion, BIC)、汉南-奎因信息准则(hannan-quinn information criterion, HQIC)、-2残差对数似然值准则(-2 res log likelihood, -2logL)[1,4-5,15,17]等, 值越小表示拟合性越好, 如果相近, 可通过χ2检验[17]并结合试验本身的特点进行判断。另外, 协方差结构模型需要估算的参数个数越少越好。从表3可以看出, 土柱试验UN和ANTE(1)模型各准则值明显低于其余5种协方差模型的值, 应优先考虑。UN模型协方差矩阵中需要估算的参数个数在所有模型中最多, 为n(n-1)/2, n为重复测量次数, 计算时可能无法收敛, 估算无法完成[5]。本例中n=7, 参数个数为21个; ANTE(1)模型需要估算的参数为2n-1, 本例中为15。综合考虑, 选用ANTE(1)模型进行F检验和均值比较。
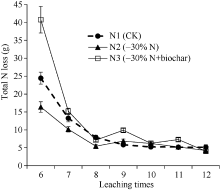
语句(7)输出结果表明, 3种氮水平平均全氮淋失量第8次与第10次淋洗相差0.94 g, 未达到5%差异显著水平。由于N*Times交互作用效果显著, 这种比较并不合适, 此处仅仅用来说明方法。语句(8)输出的结果表明, 所有淋洗平均全氮淋失量N2比N1处理低1.78 g, 差异达5%显著水平。同样原因, 这种比较在此例中不合适, 仅用于方法说明。田间试验均值间比较思路类似, 不再赘述。
一阶前依赖结构[ANTE(1)]允许不同重复测量点间的方差不同, 以及不同测量点对之间相关性和协方差不等。此很符合本研究的实际情况, 在所有协方差结构模型中, 该模型最优(表3), 进一步证实了该模型的实用性。使用ANTE(1)时, 测量点必需要按先后顺序正确排列, 但各测量点之间时间间隔不必相等。这也很符合一般作物类试验的实际情况。本研究中对不规则(UN)、空间幂相关[SP(POW)]、一阶自回归[AR(1)]、循环相关(TOEP)等协方差结构模型进行了尝试, 限于篇幅, 此处不进行深入讨论。有兴趣的读者请参阅文献[1]、[5]、[15]和[19]。
选择协方差结构模型时, 首先应排除明显无意义的协方差结构。如田间试验中, 同一小区不同时间重复测量数据一般具有相关性, VC模型不合适, 应排除。对于时间间隔不等的情况, AR(1)结构肯定不合适[1]。下一步, 可以以时间间隔为横坐标, 以对象内协方差为纵坐标作图, 考察协方差的变化规律, 初步判定合适的协方差结构。最后, 查看如表3所示的拟合性信息, 必要时进行卡方检验, 确定最合适的协方差结构。
本文的其它图/表
|