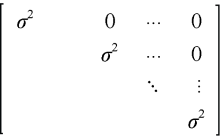运用广义线性混合模型分析随机区组重复测量的试验资料
张久权, 闫慧峰, 褚继登, 李彩斌
作物学报
2021, 47 ( 2):
294-304.
DOI: 10.3724/SP.J.1006.2021.04085
重复测量试验对同一受试对象进行多次测量, 各时间点数据间存在自相关性, 进行方差分析和均值比较时需要进行特殊处理。虽然此方法在农业等研究领域运用十分广泛, 但目前有效地相关统计方法鲜见。为了建立操作简单、实用性强、结果可靠的统计分析方法, 本研究采用SAS的广义线性混合模型(Generalized Linear Mixed Models, GLIMMIX), 以随机区组重复测量试验资料为例, 说明了协方差结构筛选、方差分析和均值比较的具体方法。结果表明, 用传统的裂区设计、多变量统计等方法会造成资料信息浪费, 统计功效降低, 缺区无法处理等问题, 甚至会导致错误的结论。GLIMMIX能很好地处理自相关问题, 功能强大, 结果可靠, 使用简单, 允许缺区, 是进行重复测量试验资料方差分析和均值比较的理想方法。目前在国内将其运用到农学类试验数据的统计分析的相关报道鲜见, 该文在本领域具有很强的实用性和创新性。
语句#
Code # | 处理组合¶
Treatment ¶ | 差值
Difference | 标准误
SE | 自由度
DF | t值
t-value | Pr > |t| | | (4a) | (1)定位法Positional | 8.05 | 4.32 | 17.85 | 1.87 | 0.0786 | | (4b) | (1)非定位法Non-positional | 8.05 | 4.32 | 17.85 | 1.87 | 0.0786 | | (5) | (2) | 10.94 | 3.19 | 20.36 | 3.43 | 0.0026 | | (6) | (3) | 6.38 | 1.73 | 33.37 | 3.70 | 0.0008 | | (7) | (4) | 0.94 | 0.60 | 31.51 | 1.58 | 0.1248 | | (8) | (5) | 1.78 | 0.77 | 28.62 | 2.31 | 0.0285 |
View table in article
表5
处理均值两两比较示例
正文中引用本图/表的段落
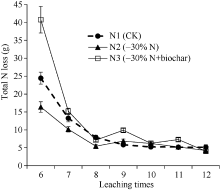
语句(4)检验第6次淋洗N1与N2处理全N淋失量差异显著性, 即进行特定时间两处理水平间的比较。语句(4a)和(4b)作用完全相同, 前者采用传统的定位式(positional)写法, 较为复杂; 后者采用新式的非定位式(non-positional)写法[18], 更为简单, 读者可以任选其一。语句(5)检验N2处理第6次淋洗与第8次淋洗全N淋失量差异显著性, 即特定处理随时间的变化差异; 语句(6)检验N1处理第7次淋洗与N2处理第9次淋洗全氮淋失量差异显著性, 即两处理水平在各特定时间点的差异, 由此可以找出最优处理组合; 语句(7)检验3种氮水平处理平均全氮淋失量, 第8次淋洗与第10次淋洗的差异显著性, 即所有处理平均随时间的变化差异是否显著; 语句(8)检验N1与N2在所有时间点平均, 全氮淋失量的差异显著性, 即两处理水平在所有时间点平均的差异, 输出结果见表5。读者可以根据需要, 进行其他处理组合间的差异显著性检验。
根据F检验结果, 土柱试验数据仅仅需要对效应显著的均值进行显著性检验, 但为了让读者全面掌握重复测量数据均值比较的方法, 下面针对“1.2 分析比较”所提出的5种情况进行说明。表5是SAS程序II输出的结果汇总。可以看出, 5种比较都能进行。语句(4a)和(4b)所得结果完全一致, 说明采用传统的定位句法和新式的非定位句法[18]能达到同样的效果, 但后者不需要用“0”占位, 更直观简洁, 书写更方便, 尤其是一些比较复杂的比较[18], 因此建议使用新式的非定位句法。
从表2可以看出, 第6次淋洗时, N2比N1的总氮淋失量低8.05 g (图1), 接近5%差异显著水准(P = 0.078), 此为特定时间(第6次淋洗)两处理水平(N1 vs. N2)间的比较; 语句(5)输出的结果表明, N2处理总N淋失量第6次比第8次淋洗高10.94 g, 差异达1%极显著水平(P = 0.0025), 我们还可以检验第6次与第8、9、10、11、12次淋洗的差异显著性, 也可以对其他时间进行差异显著性比较, 确定总N淋失量随时间的变化规律。语句(6)输出的结果表明, N1第7次淋洗比N2处理第9次淋洗全氮淋失量多6.38 g氮(表5和图1), 差异极显著(P = 0.0008)。可以继续进行两处理水平在各特定时间点的差异比较, 找出最优处理组合。
本文的其它图/表
|