欢迎访问作物学报,今天是
作物学报 ›› 2018, Vol. 44 ›› Issue (9): 1274-1289.doi: 10.3724/SP.J.1006.2018.01274
贺建波( ),刘方东,邢光南,王吴彬,赵团结,管荣展,盖钧镒()
),刘方东,邢光南,王吴彬,赵团结,管荣展,盖钧镒()
Jian-Bo HE(),Fang-Dong LIU,Guang-Nan XING,Wu-Bin WANG,Tuan-Jie ZHAO,Rong-Zhan GUAN,Jun-Yi GAI()
摘要:
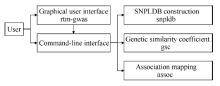
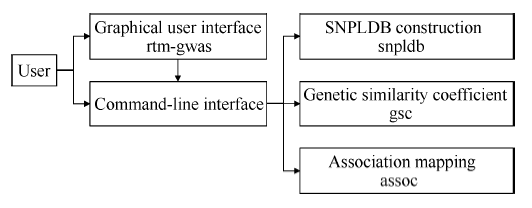
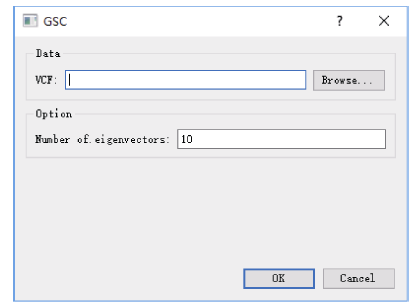
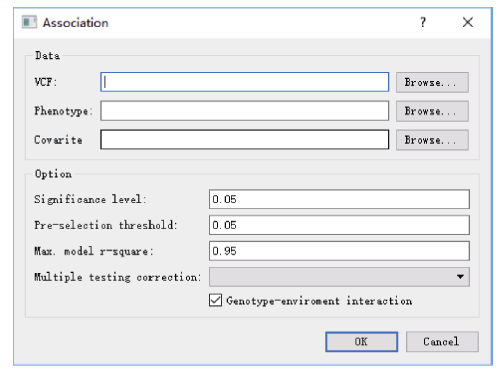
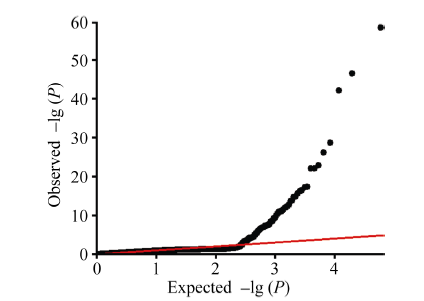
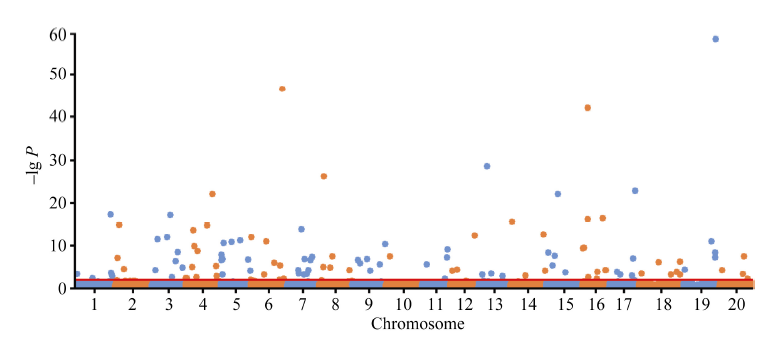
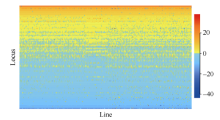
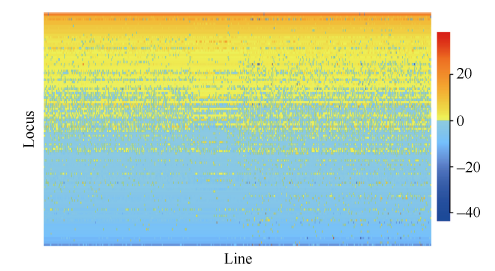
全基因组关联分析(genome-wide association study, GWAS)的理论及应用是近十几年来国内外数量性状研究的热点, 但是以往GWAS方法注重于个别主要QTL/基因的检测与发掘。为了相对全面地解析全基因组QTL及其等位基因构成, 本研究提出了限制性两阶段多位点GWAS方法(RTM-GWAS, https://github.com/njau-sri/rtm-gwas)。RTM-GWAS首先将多个相邻且紧密连锁的SNP分组, 成为具有多个单倍型(复等位变异)的连锁不平衡区段(SNPLDB)标记, 然后采用两阶段分析策略, 基于多位点复等位变异遗传模型, 在节省计算空间的条件下保障全基因组QTL及其复等位变异检出的精确度。和以往GWAS方法相比, RTM-GWAS以性状遗传率为上限, 能够较充分地检测出QTL及其相应的复等位变异并能有效地控制假阳性的膨胀。由其结果建立的QTL-allele矩阵代表了群体中所研究性状的全部遗传组成。依据这种QTL-allele矩阵的信息, 可以设计最优基因型的遗传组成, 预测群体中最优化的杂交组合, 并用以进行群体遗传和特有与新生等位变异的研究。本研究首先对RTM-GWAS方法的特点和计算程序功能进行说明, 然后通过大豆试验数据说明RTM-GWAS计算程序的使用方法。
| [1] | Visscher P M, Wray N R, Zhang Q, Sklar P , McCarthy M I, Brown M A, Yang J . 10 Years of GWAS discovery: biology, function, and translation. Am J Hum Genet, 2017,101:5-22 |
| [2] |
Pritchard J K, Stephens M, Rosenberg N A, Donnelly P . Association mapping in structured populations. Am J Hum Genet, 2000,67:170-181
doi: 10.1086/302959 pmid: 10827107 |
| [3] | Price A L, Patterson N J, Plenge R M, Weinblatt M E, Shadick N A, Reich D . Principal components analysis corrects for stratification in genome-wide association studies. Nat Genet, 2006,38:904-909 |
| [4] | Yu J, Pressoir G, Briggs W H, Vroh Bi I, Yamasaki M, Doebley J F , McMullen M D, Gaut B S, Nielsen D M, Holland J B, Kresovich S, Buckler E S. A unified mixed-model method for association mapping that accounts for multiple levels of relatedness. Nat Genet, 2006,38:203-208 |
| [5] |
Kang H M, Zaitlen N A, Wade C M, Kirby A, Heckerman D, Daly M J, Eskin E . Efficient control of population structure in model organism association mapping. Genetics, 2008,178:1709-1723
doi: 10.1534/genetics.107.080101 pmid: 18385116 |
| [6] |
Kang H M, Sul J H, Service S K, Zaitlen N A, Kong S Y, Freimer N B, Sabatti C, Eskin E . Variance component model to account for sample structure in genome-wide association studies. Nat Genet, 2010,42:348-354
doi: 10.1038/ng.548 pmid: 20208533 |
| [7] |
Zhang Z, Ersoz E, Lai C Q, Todhunter R J, Tiwari H K, Gore M A, Bradbury P J, Yu J, Arnett D K, Ordovas J M, Buckler E S . Mixed linear model approach adapted for genome-wide association studies. Nat Genet, 2010,42:355-360
doi: 10.1038/ng.546 pmid: 20208535 |
| [8] |
Pritchard J K, Stephens M, Donnelly P . Inference of population structure using multilocus genotype data. Genetics, 2000,155:945-959
pmid: 10835412 |
| [9] | Alexander D H, Novembre J, Lange K . Fast model-based estimation of ancestry in unrelated individuals. Genome Res, 2009,19:1655-1664 |
| [10] | Atwell S, Huang Y S, Vilhjalmsson B J, Willems G, Horton M, Li Y, Meng D, Platt A, Tarone A M, Hu T T, Jiang R, Muliyati N W, Zhang X, Amer M A, Baxter I, Brachi B, Chory J, Dean C , Debieu M, de Meaux J, Ecker J R, Faure N, Kniskern J M, Jones J D, Michael T, Nemri A, Roux F, Salt D E, Tang C, Todesco M, Traw M B, Weigel D, Marjoram P, Borevitz J O, Bergelson J, Nordborg M . Genome-wide association study of 107 phenotypes in Arabidopsis thaliana inbred lines. Nature, 2010,465:627-631 |
| [11] |
Huang X, Wei X, Sang T, Zhao Q, Feng Q, Zhao Y, Li C, Zhu C, Lu T, Zhang Z, Li M, Fan D, Guo Y, Wang A, Wang L, Deng L, Li W, Lu Y, Weng Q, Liu K, Huang T, Zhou T, Jing Y, Li W, Lin Z, Buckler E S, Qian Q, Zhang Q F, Li J, Han B . Genome-wide association studies of 14 agronomic traits in rice landraces. Nat Genet, 2010,42:961-967
doi: 10.1038/ng.695 pmid: 20972439 |
| [12] | Li H, Peng Z, Yang X, Wang W, Fu J, Wang J, Han Y, Chai Y, Guo T, Yang N, Liu J, Warburton M L, Cheng Y, Hao X, Zhang P, Zhao J, Liu Y, Wang G, Li J, Yan J . Genome-wide association study dissects the genetic architecture of oil biosynthesis in maize kernels. Nat Genet, 2013,45:43-50 |
| [13] | Fang C, Ma Y M, Wu S W, Liu Z, Wang Z, Yang R, Hu G H, Zhou Z K, Yu H, Zhang M, Pan Y, Zhou G A, Ren H X, Du W Q, Yan H R, Wang Y P, Han D Z, Shen Y T, Liu S L, Liu T F, Zhang J X, Qin H, Yuan J, Yuan X H, Kong F J, Liu B H, Li J Y, Zhang Z W, Wang G D, Zhu B G, Tian Z X . Genome-wide association studies dissect the genetic networks underlying agronomical traits in soybean. Genome Biol, 2017,18:161 |
| [14] | Peleman J D , van der Voort J R. Breeding by design. Trends Plant Sci, 2003,8:330-334 |
| [15] |
Huang X, Wei X, Sang T, Zhao Q, Feng Q, Zhao Y, Li C, Zhu C, Lu T, Zhang Z, Li M, Fan D, Guo Y, Wang A, Wang L, Deng L, Li W, Lu Y, Weng Q, Liu K, Huang T, Zhou T, Jing Y, Li W, Lin Z, Buckler E S, Qian Q, Zhang Q F, Li J, Han B . Genome-wide association studies of 14 agronomic traits in rice landraces. Nat Genet, 2010,42:961-967
doi: 10.1038/ng.695 pmid: 20972439 |
| [16] | Zhao K, Tung C W, Eizenga G C, Wright M H, Ali M L, Price A H, Norton G J, Islam M R, Reynolds A, Mezey J , McClung A M, Bustamante C D, McCouch S R . Genome-wide association mapping reveals a rich genetic architecture of complex traits in Oryza sativa. Nat Commun, 2011,2:467 |
| [17] |
Zeng Z B . Precision mapping of quantitative trait loci. Genetics, 1994,136:1457-1468
doi: 10.1007/s00122-012-2032-2. pmid: 8013918 |
| [18] | He J, Meng S, Zhao T, Xing G, Yang S, Li Y, Guan R, Lu J, Wang Y, Xia Q, Yang B, Gai J . An innovative procedure of genome-wide association analysis fits studies on germplasm population and plant breeding. Theor Appl Genet, 2017,130:2327-2343 |
| [19] | Zhang Y, He J, Wang Y, Xing G, Zhao J, Li Y, Yang S, Palmer R G, Zhao T, Gai J . Establishment of a 100-seed weight quantitative trait locus-allele matrix of the germplasm population for optimal recombination design in soybean breeding programmes. J Exp Bot, 2015,66:6311-6325 |
| [20] | Meng S, He J, Zhao T, Xing G, Li Y, Yang S, Lu J, Wang Y, Gai J . Detecting the QTL-allele system of seed isoflavone content in Chinese soybean landrace population for optimal cross design and gene system exploration. Theor Appl Genet, 2016,129:1557-1576 |
| [21] | Li S, Cao Y, He J, Zhao T, Gai J . Detecting the QTL-allele system conferring flowering date in a nested association mapping population of soybean using a novel procedure. Theor Appl Genet, 2017,130:2297-2314 |
| [22] | Gabriel S B, Schaffner S F, Nguyen H, Moore J M, Roy J, Blumenstiel B, Higgins J , DeFelice M, Lochner A, Faggart M, Liu-Cordero S N, Rotimi C, Adeyemo A, Cooper R, Ward R, Lander E S, Daly M J, Altshuler D . The structure of haplotype blocks in the human genome. Science, 2002,296:2225-2229 |
| [23] | Patterson N, Price A L, Reich D . Population structure and eigenanalysis. PLoS Genet, 2006,2:e190 |
| [24] | Price A L, Patterson N J, Plenge R M, Weinblatt M E, Shadick N A, Reich D . Principal components analysis corrects for stratification in genome-wide association studies. Nat Genet, 2006,38:904-909 |
| [25] |
VanRaden P M . Efficient methods to compute genomic predictions. J Dairy Sci, 2008,91:4414-4423
doi: 10.3168/jds.2007-0980 pmid: 18946147 |
| [26] | Scheet P, Stephens M . A fast and flexible statistical model for large-scale population genotype data: applications to inferring missing genotypes and haplotypic phase. Am J Hum Genet, 2006,78:629-644 |
| [27] |
Buckler E S, Holland J B, Bradbury P J, Acharya C B, Brown P J, Browne C, Ersoz E, Flint-Garcia S, Garcia A, Glaubitz J C, Goodman M M, Harjes C, Guill K, Kroon D E, Larsson S, Lepak N K, Li H, Mitchell S E, Pressoir G, Peiffer J A, Rosas M O, Rocheford T R, Romay M C, Romero S, Salvo S , Sanchez Villeda H, da Silva H S, Sun Q, Tian F, Upadyayula N, Ware D, Yates H, Yu J, Zhang Z, Kresovich S, McMullen M D. The genetic architecture of maize flowering time. Science, 2009,325:714-718
doi: 10.1126/science.1174276 pmid: 19661422 |
| [28] |
Meuwissen T H, Hayes B J, Goddard M E . Prediction of total genetic value using genome-wide dense marker maps. Genetics, 2001,157:1819-1829
doi: 10.1017/S0016672301004931 pmid: 11290733 |
| [1] | 冯建英,温阳俊,张瑾,章元明. 植物关联分析方法的研究进展[J]. 作物学报, 2016, 42(07): 945-956. |
|
||